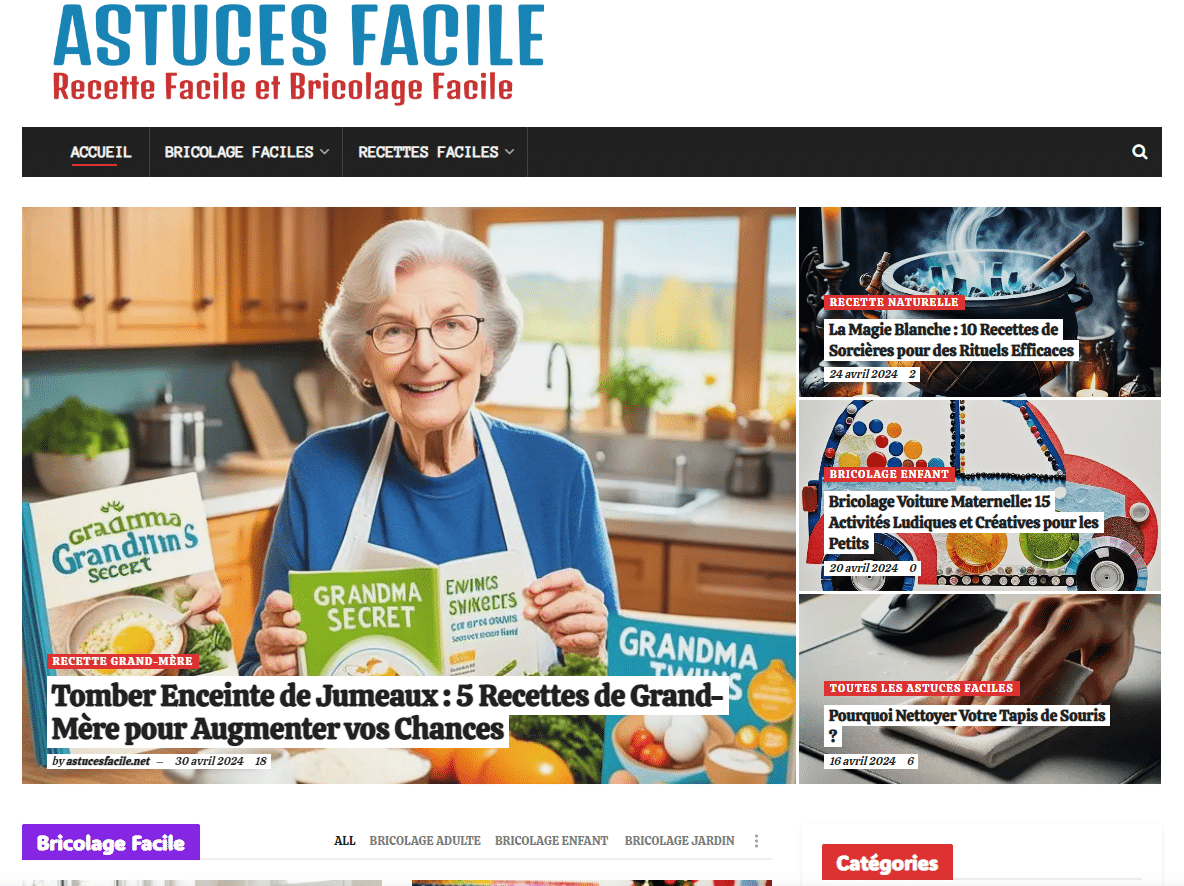
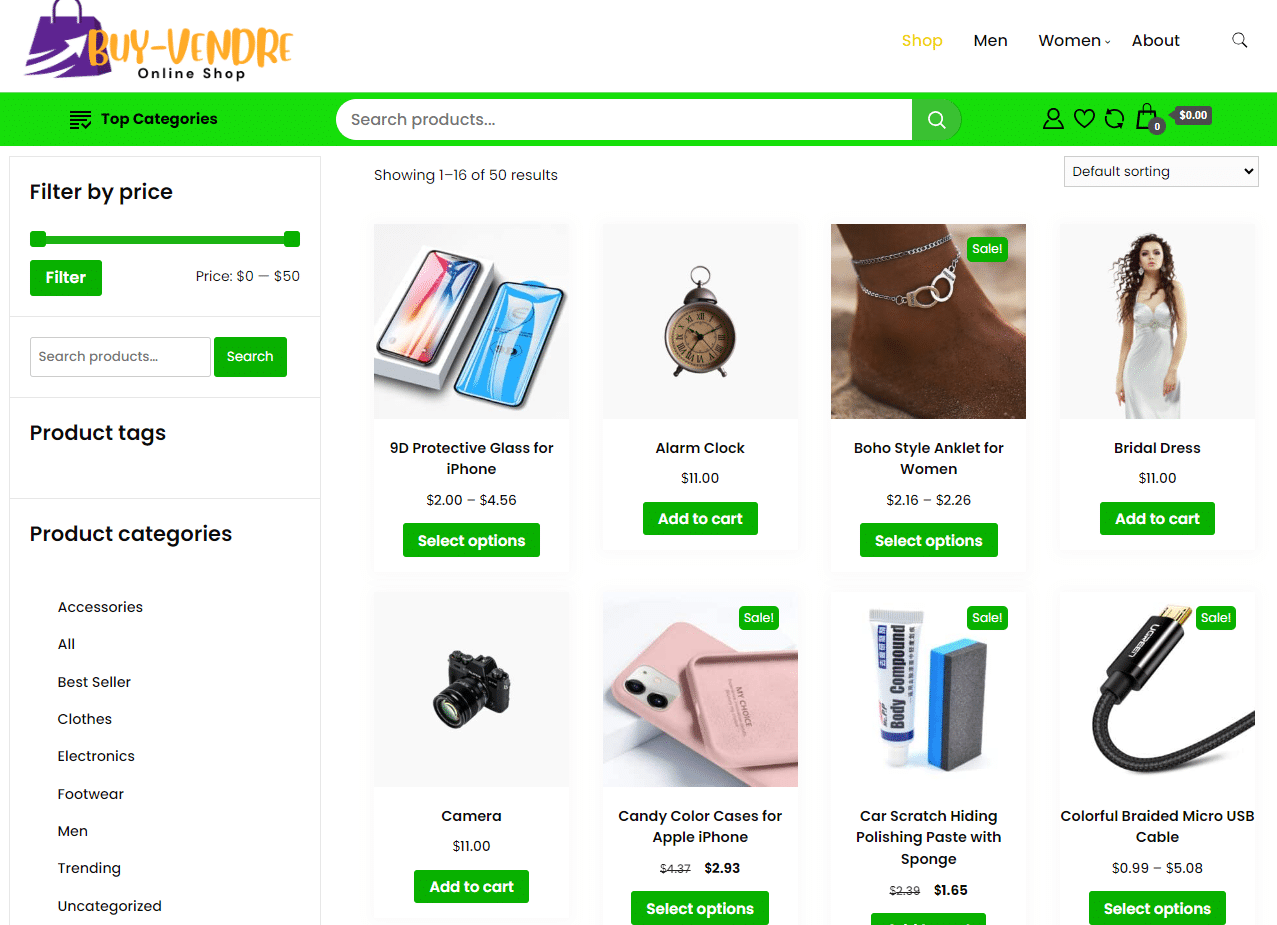
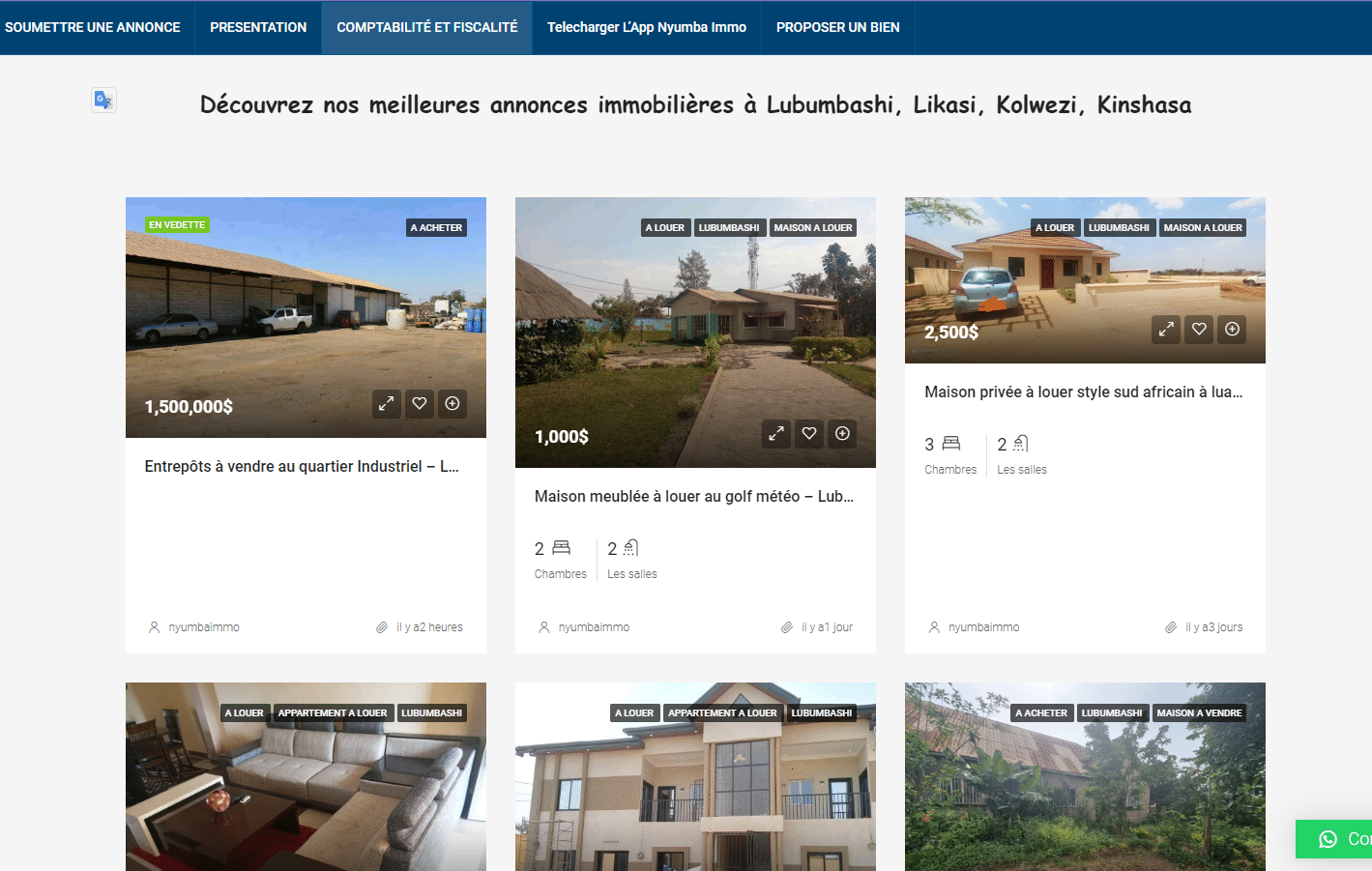
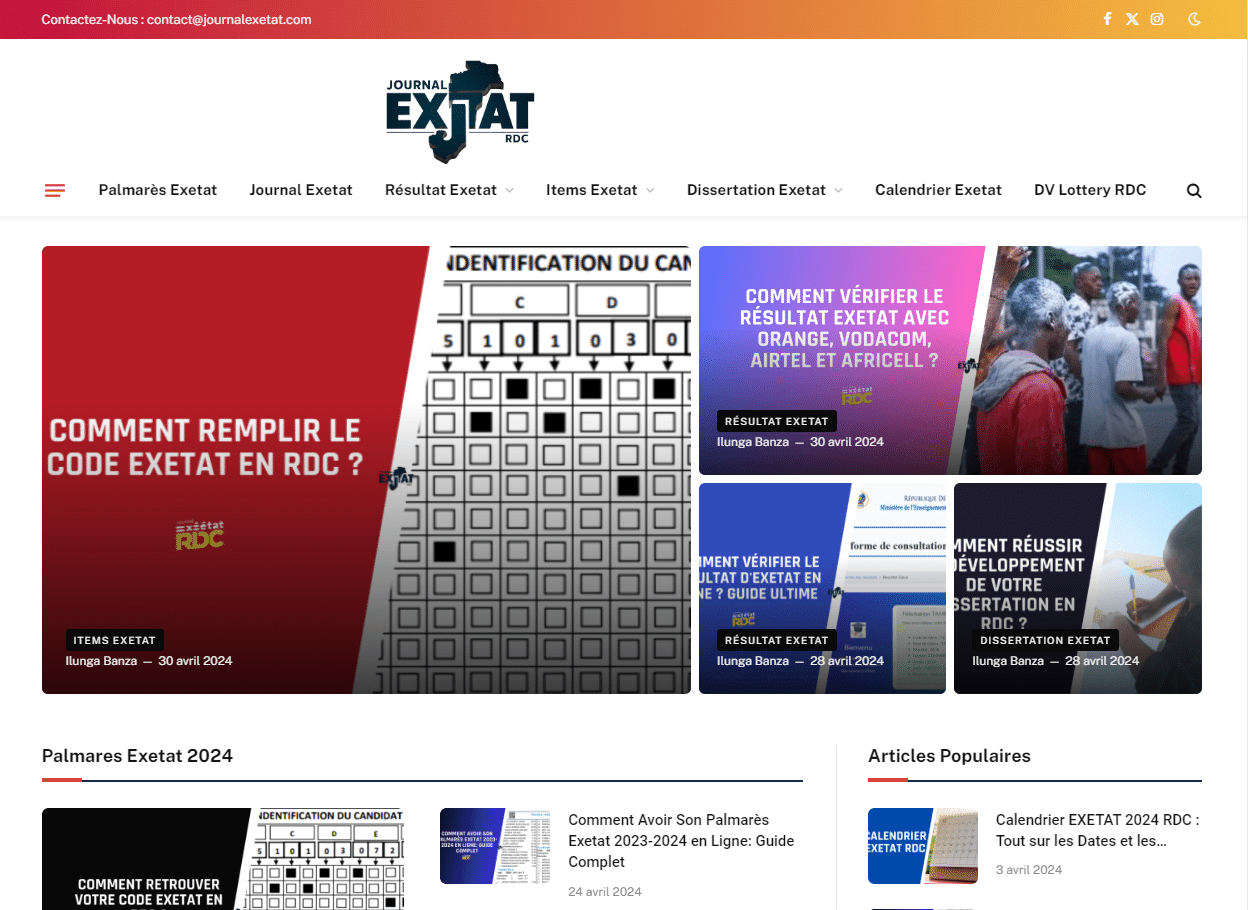
Votre site web est le cœur de votre réacteur digital. Je ne me contente pas de créer des sites esthétiques ; je bâtis des plateformes ultra-performantes, techniquement irréprochables et conçues dès la première ligne de code pour le SEO de 2025.
Rédacteur Web / Copywriter SEO
À l’ère de l’IA, le contenu générique ne suffit plus. Je conçois et rédige pour vous du contenu qui va au-delà des mots-clés pour atteindre l'excellence E-E-A-T (Expérience, Expertise, Autorité, Confiance).
Consultant SEO/SEA
Ne visez plus le trafic, visez la croissance rentable. En tant que consultant, ma mission est de devenir votre partenaire stratégique en acquisition. J'analyse la SERP avec une vision 2025 pour déceler les failles de vos concurrents et construire votre autorité thématique durable (SEO)
NOS RÉALISATIONS (Agence SEO & Web Lubumbashi/Kinshasa)
Contactez-nous dès aujourd’hui pour une analyse gratuite de vos besoins et définir ensemble la stratégie content marketing qui vous permettra d’atteindre vos objectifs.